Resource Description Framework (RDF) によって、ユーザーは Web 上の文書や、現実世界に存在する人や組織、また事柄や物などの概念について、コンピュータが処理可能な状態で説明することができるようになります。そして、機械処理可能な情報を Web 上に公開することで、セマンティック Web を構築することができるのです。Web と RDF をリンクし、またそのフレームワークを提供するにあたり、URI (Uniform Resource Identifier) はとても重要な概念です。この文書は、URI の効果的な利用法をガイドラインとして提示します。具体的には、303 URI と ハッシュ URI という、二つの方法について解説します。また、これらの手法を利用する Web サイトの例を取り上げ、さらに他の方法が持つ問題点についても簡単に説明します。
セマンティック Web とは、統合にかかるコストを最小限に抑えたうえで、機械処理可能なデータを共有できる、分散的でワールドワイドな情報システムのことです。セマンティック Web への課題として、共有されたデータモデルによる分散的な世界のモデル作りと、データやスキーマの公開・発見・利用が可能なインフラの構築が挙げられています。ユーザーにとって、"そのままの状態で今すぐ (raw and now)" [Give]、またポータブルなデータフォーマット [DP] で情報を入手することが利益となります。しかし、情報発信者は多くの場合、固定されたユーザーインターフェースや、HTML によりデータを公開しています。つまり、「どのようにすれば、リソースに関する情報をその情報に興味を持っているユーザーやアプリケーションに対して公開できるのか。」という疑問がこの問題の根幹なのです。
セマンティック Web では、すべての情報が リソース (resources) に関する ステートメント (statements) として表されます。たとえば、「Example.com という会社のメンバーは Alice と Bob です。」や「Bob の電話番号は "+1 555 262" です。」、「この Web ページは Alice が製作しました。」などです。リソースは Uniform Resource Identifier (URI) [RFC3986] で識別されます。このモデリングによるアプローチが、Resource Description Framework (RDF) [RDFPrimer] の真髄なのです。より詳しい説明は、N3 入門にまとめられています [N3Primer]。
RDF を用いることで、このようなステートメントを企業の Web サイトから発信することができます。他の人はそのデータを読み、また既存の情報にリンクさせ、独自に情報を公開することもできます。結果として、世界の分散的なモデルを構築することができるのです。このモデルによって、ユーザーはデータを処理するアプリケーションを自由に選ぶことができるようになります。たとえば、Alice の公開したアドレスを、あなたのアドレス帳で読むときなどに、その利便性が活かされます。
さて、Web 上にある文書は常に URI (一般的に Uniform Resource Locators や URL と呼ばれています) によりアドレスされます。URI は、Web ページに関する RDF ステートメント (RDF statements) を作成する時にとても便利ですが、危険なものでもあります。なぜなら、その Web ページと、そのページで説明されている物やリソースとの区別がつきにくいからです。
では、どんな URI を RDF で用いればよいのでしょうか。たとえば、Example Inc. という会社なら、その Web サイトのトップページは http://www.example.com/ で識別させることができるでしょう。しかし、どの URI が Web サイトではなく、その会社や組織自体を識別するものになるのでしょうか。HTML 文書や RDF ファイルを含めたすべてのコンテンツを、その URI から抽出しなければならないのでしょうか。この文書はそのような疑問に対し、関連する使用に基づいて解説をおこなう文書です。私たちは人や製品、場所、アイデア、オントロジーにおけるクラスなどの概念といった Web ページではないものに、どう URI を使えばいいのかを説明します。また、セマンティック Web が Web の一部として理解されるために、いくつかの例を挙げ解説します。
2. Web 文書の URI
では、例から始めましょう。Example Inc. という、"エクストリームなギターアンプ (Extreme Guitar Amplifiers)" を生産している会社があり、その Web サイトは http://www.example.com/ だとします。サイトには各従業員について書かれたページがあり、名前とその他の情報が掲載されています。Example Inc. には Alice と Bob というふたりの従業員がいるので、Web サイトは次のような構造になっています。
http://www.example.com/
Example Inc. のホームページ
http://www.example.com/people/alice
Alice のホームページ
http://www.example.com/people/bob
Bob のホームページ
今までの Web と同じように、これらのページは Web 文書 (Web documents) です。すべての Web 文書は URI を持ちます。しかし、Web 文書はファイルそのものではありません。一つの Web 文書は、異なる言語やフォーマットで表すことができるのです。しかし、一つのファイル、たとえば PHP スクリプトは、それぞれ異なる URI を持つ、膨大な数の Web 文書を生成することがあるかもしれません。Web 文書とは URI を持ち、HTTP リクエストに応じて識別されたリソース 表現 (representations) (HTML や JPEG、RDF のようなフォーマットによるレスポンス) を返すことができるものとして定義されています。 Architecture of the World Wide Web, Volume One [AWWW] などの技術的な文書では、情報リソース (Information Resource) という言葉が Web 文書 の代わりに使われています。
今までの Web では、URI は 優先的に、Web 文書に対し使われていました。たとえば、リンクを張ったり、ブラウザからアクセスするときなどです。しかし、リソースの 識別子 (identity) としての側面はあまり重要ではありませんでした。URL はただ、私たちがブラウザにタイプしたときに現れるものを識別していただけなのです。
2.1. HTTP と コンテントネゴシエーション
Web クライアントとサーバーは、HTTP プロトコル [RFC2616] を介して Web 文書の各種表現をリクエストし、そのレスポンスを受け取ります。HTTP は異なるフォーマットや言語を持つ一つの Web 文書を提供するために、コンテントネゴシエーション (content negotiation) という強力なメカニズムを備えています。
GET /people/alice HTTP/1.1
Host: www.example.com
Accept: text/html, application/xhtml+xml
Accept-Language: en, de
サーバーは次のように応答するでしょう。
HTTP/1.1 200 OK
Content-Type: text/html
Content-Language: en
Content-Location: http://www.example.com/people.en.html
そして、レスポンスにあるとおり英語版の HTML 文書が返ってきます。コンテントネゴシエーション はこの流れのなかで行われています [TAG-Alt]。サーバーはリクエスト内の Accept-Language ヘッダを解釈し、該当するリソースの英語版を返すと決定します。さて、英語版リソースの URI はここで Content-Location ヘッダに戻されます。これは必須事項ではありませんが、推奨されている挙動です ([CHIPS] 7.2 をご覧ください)。こうすることで、クライアントはこの URI が特定の表現 (この場合は英語版の文書) に結びついていると理解し、また検索エンジンは異なる URI から別のリソースを参照することができます。つまり、同じリソースに複数の表現を持たせることが可能となるのです。
RDF の標準構文である RDF/XML は、application/rdf+xml という、独自の content type を持っています。よって、コンテントネゴシエーションにより、旧来の Web ブラウザには HTML 版の Web 文書を、そしてセマンティック Web ユーザーエージェントには RDF 版を提供することができるのです。また、サーバーに Notation3 [N3] 版や TriX [TriX] 版など、別の構文で RDF を提供させることも可能となります。
3. 実世界のオブジェクトにつける URI
セマンティック Web において、URI は Web 文書のみを識別するわけではありません。人や車など、実世界にあるものも識別します。さらには、抽象的な概念や、ユニコーンなど架空の生き物まで識別します。私たちはこれらすべてを 実世界のオブジェクト (real-world objects)、または単に 「もの」 と呼んでいます。
さて、実世界のオブジェクトにつけられた URI から、私たちはどのようにして URI が識別するオブジェクトを見つけることができるのでしょうか。それぞれ独立している情報システムの相互運用性を確保するためにも、何らかの回答を見つける必要があります。検索エンジンのように、識別されたリソースを探すようなサービスがあればよいのかもしれません。しかし、このような単一のやりかたは Web の分散的な性質に反してしまいます。
リソースの説明 (resource descriptions) を検索するサービスには、Web 自身を活用するべきなのです。なぜなら、Web はとても堅牢でスケーラブルな情報公開システムだからです。URI が言及されるたびに、私たちは関連する情報の説明や、関連するデータへのリンクを検索して見つけだします。これはとても重要なことであるため、これを クールな URI における一番大きな要件とします。
1. Web にあること (Be on the Web.)
URI のみが与えられた状態において、機械や人間はその URI により識別されたリソースの説明を Web から得られるようにするべきです。このような検索メカニズムは、URI が何を識別するのかを理解し、その理解を共有する際にとても重要です。また、機械は RDF データを受け取り、人間は HTML など読むことのできる表現を受け取るべきです。また、その際には Web の標準通信プロトコルである、HTTP が利用されるべきです。
Example Inc. が、従業員のコンタクト情報をセマンティック Web 上に公開し、彼らのビジネスパートナーがそのデータをアドレス帳に登録できるようにしたいと考えているとします。たとえば、Alice に関する次のようなステートメントが、N3 構文 [N3] により公開されているとします。
<URI-of-alice> a foaf:Person;
foaf:name "Alice";
foaf:mbox <mailto:alice@example.com>;
foaf:homepage <http://www.example.com/people/alice> .
識別子は、それが文書に対するものなのか、または他のリソースに対するものなのか、混乱がないようにはかるべきです。URI が識別するのは一つのものだけとされているため、一つの URI が Web から取得可能な文書と、実世界のオブジェクトの両方を示すことはできないのです。
しかしこの二つの要件は、互いに矛盾しているように感じます。もし文書の URI を実世界のオブジェクトを識別するために用いることができないのならば、それらが持つ URI からどのように表現を取得することができるのでしょうか。したがって、リソースの URI のみを与えられたとき、それを説明する文書をどのように見つけるのか、また標準の Web 技術を用いてどう実装するのかが課題となってきます。
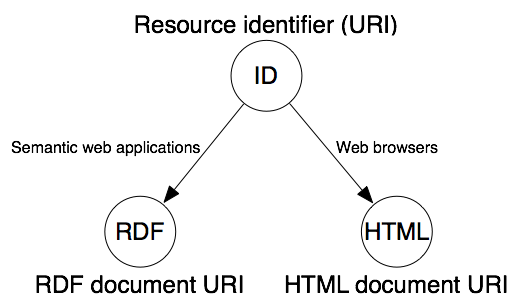
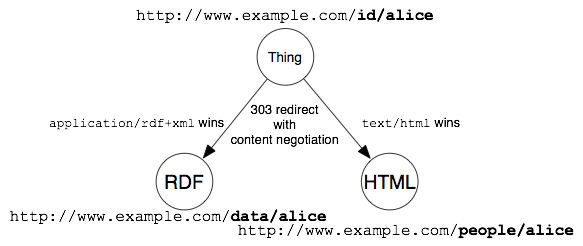
次に示す画像は、リソースとそれを表現する文書の理想的な関係を表しています。
3.1 Web 文書と実世界のオブジェクトの識別
重要なのは、URI を利用することで、(Web の外に存在しうる)「もの」と、「もの」を説明する Web 文書のどちらをも識別することが可能だということです。たとえば、人物である Alice が彼女のホームページで説明されているとします。Bob はその ホームページの 見た目が好きではありませんが、Alice という人は魅力的だと思っています。この違いを説明するには、Alice に一つ、そして Alice について説明するホームページや RDF 文書に一つ、計二つの URI が必要となります。問題は、「もの」と文書のどちらも存在している場合と、文書のみが存在している場合について、どこで線引きを行うかということです。
W3C のガイドライン ([AWWW], section 2.2.) によれば、リソースがすべての重要な性質をメッセージとして伝達できる場合において、それは Web 文書 (ガイドラインでは 情報リソース と表記) になるとされています。例として Web ページや画像、製品カタログといったものが挙げられます。
HTTP では、Web 文書にアクセスがあったとき、200 レスポンスコードが送られます。このため Web 文書ではなく、実体を識別する URI を公開するときには、異なる設定が必要となります。
次のセクションでは、「もの」に対する URI を作成する方法について、またクライアントが標準的な Web 技術を利用して「もの」の説明を取得するための方法について解説します。
4. 二つの解決策
実世界のオブジェクトを識別するための要件を満たす解決策は、二つ存在します。303 URI と呼ばれる手法と、ハッシュ URI と呼ばれる手法です。それぞれに長所と短所があるため、状況によりこれらを使い分けることになります。
次に解説する二つの解決策は、HTML 文書とともに配信されるスタンドアロンな RDF/XML 文書というように、RDF データと HTML データが分けられて配信されるというシナリオに対応するものです。メタデータは RDFa [RDFa Primer] や microformats、また GRDDL [GRDDL] のメカニズムなどによって、HTML に埋め込むことができます。このような場合において、RDF データは返される HTML 文書から抽出されることとなります。
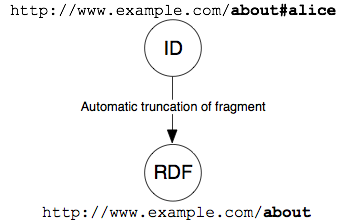
クライアントが ハッシュ URI からリソースを取得するとき、HTTP プロトコルはその URI につけられたフラグメントを、サーバーからリクエストする前に取り除くことが必須とされています。これは、ハッシュを持つ URI は直接取得することができないということであり、つまりハッシュ付き URI は Web 文書を識別するものに必ずしもならないということなのです。この特徴を利用し、私たちはハッシュ付き URI を、曖昧さを残すことなく、非文書リソースを識別するために利用することができます。
Example Inc. がハッシュ URI を使う場合、会社、Alice、Bob を表す URI は次のようなものになります。
http://www.example.com/about#exampleinc
Example Inc. という会社
http://www.example.com/about#bob
Bob という人物
http://www.example.com/about#alice
Alice という人物
クライアントはこれらの URI をリクエストする前に、そのフラグメントを取り除きます。結果として、次の URI をリクエストすることになります。
http://www.example.com/about
Example Inc. や Bob、Alice を説明する RDF 文書
Example Inc. はこの URI から、各リソースを説明する RDF 文書を提供することができます。各リソースは先ほどのハッシュ付きの URI を用いて説明されます。
次の図では、コンテントネゴシエーションを用いない、ハッシュ URI の利用法を説明しています。
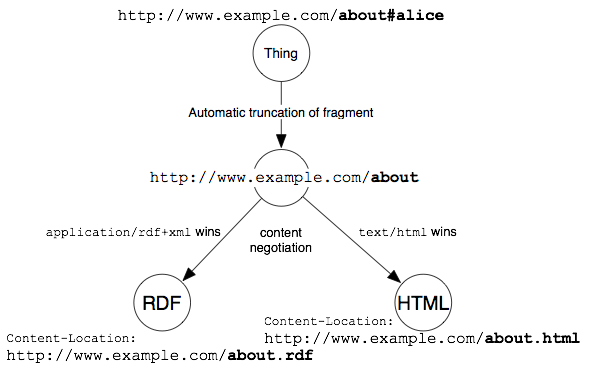
コンテントネゴシエーション (Section 2.1. を参照) を用い、about という URI から HTML または RDF 表現にリダイレクトを行うという方法もあります。このときどちらにリダイレクトされるかは、Section 4.7 にある通り、クライアントとサーバーの設定によります。ハッシュ URI が HTML 文書の一部、または RDF 文書を表すときは、Content-Location ヘッダを設定すべきです。
次の図は、コンテントネゴシエーションを用いるハッシュ URI の使い方を解説しています。
4.2. 303 URI で一つの包括的な文書に転送する
二番目の解決策は、特別な HTTP ステータスコード 303 See Other を利用し、リクエストしたリソースが通常の Web 文書ではないということを示す方法です。Web アーキテクチャでは、「もの」を表すリソース (URI) が 200 を返すのは適切ではないとしています。なぜなら、そのリソースに関する適切な表現は Web 上に存在することがないからです。しかしながら、リソースに関する情報を提供することはとても有用であり、また便利です。このため、W3C の Technical Architecture Group は、httpRange-14 resolution [httpRange] というメッセージにおいて、リクエストした「もの」に関する情報をまとめた文書へ誘導するという解決策を提示しています。303 ステータスコードを利用することで、リソースが実世界に存在するオブジェクトそのものを表すのか、またはリソースを表現する情報なのかをはっきり区別することができます。
303 はリダイレクトを行うステータスコードです。サーバーはこのステータスコードにより、リソースを表現する文書の場所を伝えることができます。もし、リクエストが 200 OK といった一般的な 2XX ステータスコードで返された場合、クライアントはその URI が Web 文書だと知ることができます。
Example Inc. がこの解決策をとる場合、次の URI により、会社自身と、Alice、Bob を表すことができます。
http://www.example.com/id/exampleinc
Example Inc. という会社
http://www.example.com/id/bob
Bob という人物
http://www.example.com/id/alice
Alice という人物
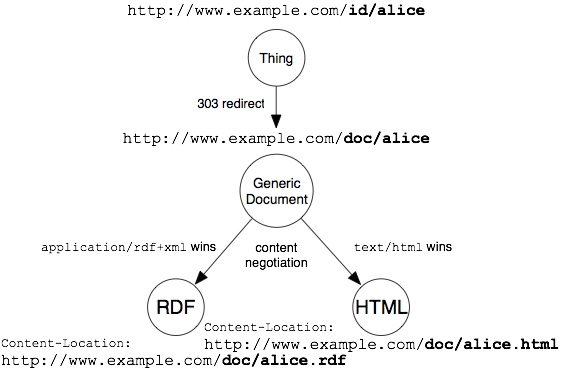
Web サーバーは、303 ステータスコードと Location HTTP ヘッダのついた URI へのリクエストすべてに答えるよう設定される必要があります。Location ヘッダにより提供される URL はリソースを表現する文書のものとなります。例としては、http://www.example.com/id/alice という人物そのものの URI から、http://www.example.com/doc/alice という文書の URI へリダイレクトするなどが考えられます。
コンテントネゴシエーションは、文書の URI から HTTP リクエストによって表現を取得するときに利用されます。サーバーは HTML または RDF (またはその他の形式) のどれを返すかを決定し (Section 4.7 を参照) 、Content-Location ヘッダにより表現の URI を指定します。
この設定では、サーバーは識別子の URI から文書の URI へ転送しています。こうすることで、クライアントは文書をブックマークしたり、その他の処理を行うことができるという利点があります。ユーザーが RDF を理解するクライアントを利用している場合、文書をブックマークし、別のユーザー (またはデバイス) に送信し、そのユーザーは送信された文書から HTML 版 または RDF 版を取得するということも可能です。また、サーバーは新しい言語の表現をあとから追加することもできます。これは「もの」自身の URI が基点となっているためで、表現を増やしても、「もの」自身の URI に影響があるわけではないのです。包括的な文書リソースの背景は [GenRes] で解説されています。
各 RDF 文書は、説明されたリソースを識別するため、適切なリソースについて説明したステートメントを含むでしょう。ステートメントにはもとの URI である http://www.example.com/id/alice などを利用します。
4.4. 303 とハッシュの選択
ハッシュ URI と 303 URI、一体どちらのアプローチが良いのでしょうか。ハッシュ URI は HTTP の往復を減らすことができるため、待ち時間を節約することができます。ハッシュ URI では、URI にハッシュを含まない共通部分を持ちます。たとえば、三つのリソース http://www.example.com/about#exampleinc、http://www.example.com/about#alice、http://www.example.com/about#bob は、http://www.example.com/about へのリクエストを一回行うだけで取得することができます。しかし、このアプローチには欠点もあります。たとえ #product123 のみに興味があるクライアントでも、他のリソースが同じファイルにあるため、すべてを取得する必要があるのです。この点において 303 URI はフレキシブルであり、各リソースに対してそのリダイレクト先を個別に設定することができます。たとえば、リソースごとに解説文書を用意する、すべてのリソースを解説する一つの文書を用意する、またはこれらを組み合わせて利用することもできます。この場合、リダイレクトのポリシーを後で変更することもできます。
FOAF など、303 URI をオントロジーの定義に利用する場合があります。このとき、ネットワークの遅滞によりクライアントのパフォーマンスが低下する可能性があります。リダイレクト数が多くなるにつれ、待ち時間が長くなってしまうのです。これは、リダイレクトから語彙を検索するクライアントは、たとえ最初のリクエストで必要な情報すべてを得たとしても、なお多くのリクエストを投げてしまうことがあるからです。
303 URI に解決策では大量のデータセットをホストする場合、クライアントはすべてのデータを、多くのリクエストを用いて取得しようとします。SPARQL エンドポイントや類似する複雑なクエリーをサーバー側で直接解釈するサービスを提供することを推奨します。大きなデータを HTTP によって取得させるよりも効率が良いからです。
どのようなフラグメント識別子も妥当なものとなります。上記の this も、おすすめする一つの例です。
結論
ハッシュ URI は、すべてのリソースが共に発展する、小さなリソースセットにおいておすすめです。理想的なケースとして、定義が共に利用され、また将来的に管理できない規模になることのない RDF スキーマや OWL オントロジーなどが挙げられます。
コンテントネゴシエーションを用いないハッシュ URI は、静的な RDF ファイルを Web サーバーにアップロードするだけで実現できます。特別なサーバーの設定も必要ありません。このシンプルさが、やっつけ仕事的な RDF の公開において人気となっている理由です。
bob#this のような URI は、単一文書で管理できないほどデータ量が増える、またはその可能性がある大きなデータセットに対し用いられるべきです。この場合、303 URI を利用し、見栄えの良い URI でデータを提供することができるでしょう。しかしながら、実行時のパフォーマンスとサーバーの負荷に影響をあたえます。
短い URI は基本的に覚えやすいものです。セマンティック Web サーバーをデバッグするときにも楽ですし、またメールのなかで改行されることもありません。
持続性 (Stability.)
あるリソースを識別する URI を決定したとき、その URI は可能な限り長く残るようにすべきです。10 年、もしくは 20 年先のことを考えましょう。.php や .asp など実装固有の情報は、将来採用する技術が変更されることを考え、URI から省きましょう。
管理のしやすさ (Manageability.)
管理できるようなかたちで URI を発行しましょう。一つよい方法として、URI のパスに現在の年を含めるというものがあります。こうすることで URI スキーマを毎年変更できるため、古い URI を壊すことはありません。また、すべての 303 URI をたとえば http://id.example.com/alice という、専用のサブドメインから発行するようにしましょう。これにより、URI を処理するサブシステムとの統合が容易になります。
4.6. リンクする
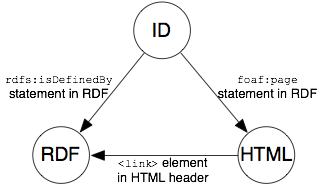
リソース識別子や RDF 文書の URL、また HTML 文書の URL など、一つの実世界オブジェクトに関わる URI は、互いの関係を情報の消費者が理解できるように、すべて明示的にリンクすべきです。たとえば、303 URI を用いた Example Inc. の場合、Alice に関係している URI は三つ存在しています。
クライアントはまた、HTTP ヘッダから同様のリンク情報を推測することができます。たとえば、「『もの』は 303 リダイレクトにより導かれた Web 文書で説明されている」や「Content-Location リソースは、包括的な文書のうち、内容固有のバージョンを指す」などです。なお、オントロジーとこれらの関係については触れません。
次の画像は、RDF と HTML 文書がそれぞれの URI をどのように関係させるかを示すものです。
4.7. 実装とコンテントネゴシエーション
W3C の Semantic Web Best Practices and Deployment Working Group は、Apache Web Server 上で、この文書で提示した解決策をどのように実装するかを説明した文書を公開しています。Best Practice Recipes for Publishing RDF Vocabularies [Recipes] では、RDF 語彙 の公開について多く触れていますが、基となる考えは、静的なファイルから公開される他の RDF データセットにも適用できるものとなっています。
しかし、特にコンテントネゴシエーション関し、Recipes は重要な詳細について触れていません。Tabulator extension をインストールした Firefox のように HTML と RDF のどちらをも理解するクライアントにおいて、コンテントネゴシエーションはもうすこし難しいものなのです。
最初の URI を一般的な Web ブラウザに入力すると、Wendy Hall の HTML 版ページにリダイレクトされます。このページには、彼女について Web に公開されているデータのすべてを表示しています。また、このページから彼女自身の URI や、彼女についての RDF 文書へのリンクが張られています。
D2R Server は、リレーショナルデータベースのデータをガイドラインに従い、セマンティック Web 上に公開するオープンソースのアプリケーションです。このアプリケーションは、303 URI とコンテントネゴシエーションを採用しています。たとえば、DBLP Bibliography Database の D2R Server では、数千の目録データと、その著者についての情報を公開しています。303 リダイレクトからつながる URI の例は、次の通りです。
Semantic MediaWiki は、オープンソースのセマンティック Wiki エンジンです。ページ作成者は特殊な wiki 構文を利用し、wiki 記事にセマンティックな属性や関係を付加することができます。ソフトウェアは、各記事にそのトピックを識別する 303 URI を生成し、また属性や関係から RDF による説明を提供します。Semantic MediaWiki の利用例として OntoWorld wiki があります。カールスルーエ市の記事を見てみましょう。
RDF 文書の URI は理想的なものではあまりありません。実装固有の情報 (php) や、クエリー部分とパスのどちらにもある、「RDF を出力する」という情報です。もっとクールな URI はたとえば http://ontoworld.org/rdf/Karlsruhe でしょう。この URI であればコンテントネゴシエーションを用いて、RDF や RIF (Rule Interchange Format) などでデータを配信できるからです。
6. 他のリソース命名案
これまでリソースの命名に関し、さまざまな提案がなされてきました。しかし、多くの提案は特定の状況下における解決策であり、Section 3 で解説した「Web上にあること」と、「曖昧でないこと」という二つの指針に沿わないと感じました。つまり、標準技術ベースで、分断されていない、分散的なセマンティック Web を構築するために利用できる、一般的な解決法ではないのです。ここではそのような二つの案について解説します。
6.1. 新たな URI スキーム
HTTP URI は既に Web リソースと Web 文書を識別していますが、他の種類のリソースについては識別していません。では、それら他のリソースを識別するため、新しい URI スキームを作ればよいのではないでしょうか。新しい URI スキームを利用することにより、Web 文書とその他のリソースを、URI の先頭を見るだけで判別することができるのです。たとえば、info スキームを用い、本を識別することができます。LCCN 番号に基づいて本を識別する場合は、info:lccn/2002022641 のようになります。
Magnet は Web サイトと、ファイル管理ツールのようなローカルで動作するユーティリティをシームレスに統合するためのオープンな URI スキームです。この URI はハッシュ値に基づいており、次のようになっています。 magnet:?xt=urn:sha1:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C
info: URI スキーム は、既にパブリックな名前空間の下で識別子を持っている情報を識別するために提案されました。この URI の例として、LCCN 番号 (info:lccn/2002022641) やデューイ十進分類法 (info:ddc/22/eng//004.678) が挙げられます。
Tag URI の考えは、衝突のない URI をドメイン名と URI を割り当てた日付によって作成するというものです。将来ドメインの所属が変わったりしても、URI は一義的な状態を保つことができます。例: tag:hawke.org,2001-06-05:Taiko
XRI は抽象的な識別子のために、そのスキームと解決プロトコルを定義しています。基本的な考えは、ワイルドカードを含む URI を用い、組織やサーバーなどの変更に対応するというものです。例として、@Jones.and.Company/(+phone.number) や xri://northgate.library.example.com/(urn:isbn:0-395-36341-1) といったものが挙げられます。
真に実用的になるために、新しい URI スキームは、識別されるリソースに関する情報にアクセスするためのプロトコルも定義されている必要があります。たとえば、ftp::// URI スキームはリソース (FTP サーバー上のファイル) と、リソースにアクセスするためのプロトコル (FTP プロトコル) を識別しています。
新しい URI スキーマのいくつかは、このようなプロトコルを提供していません。他のスキームについては、HTTP プロトコルを用いてリソースの説明を取得できるような Web サービスを提供しています。識別子がサービスに渡されると、情報を中央データベースや連合データベースから検索するのです。この方法の問題は、サービスの欠陥によりシステムが利用できなくなることです。
他の欠点として、標準化団体への依存が挙げられます。新しいパートを info: 空間に登録するには、標準化団体にコンタクトを必要があります。このことや、また URI の作成ライセンス料を払う必要が出てきた場合、その URI の普及が遅くなってしまいます。たとえば ISBN など、すべての URI が一意であることを保証したい場合には、標準化団体の存在は望ましいでしょう。しかし、これは標準化組織により保持・管理される HTTP 名前空間内の URI によって実現することができるのです。
標準化団体への依存や、検索可能性 (retrievability) のなさ、また特許や法的な事項が明らかにされていない場合、新しい URI スキームの普及に影響があるでしょう。もし特許のある技術を利用している場合、実装者は Royalty-Free なライセンスがあるかどうかを確認すべきです。
リソースとその説明を分けてとらえるという要件により、複数の URI を調整することが必要となってきます。このような場合に利用できる便利なテクニックとして、HTML 文書から RDF データへのリンクを埋め込む、RDF ステートメントを利用し URI の関係を説明する、コンテントネゴシエーションを利用して適切な説明をもつリソースへリダイレクトするなどがあります。
8. 謝辞
まず、Tim Berners-Lee 大変感謝しています。彼は私たちが TAG の解決策を理解するにあたり、チャットでのリクエスト に答え、またメールにて詳しい説明を提供するなど、多くの時間を割いてくれました。また特に、この文書のレビューを行い、TAG の考えと異なる多くの論拠について本質的なフィードバックを 2007 年 6 月 と 2007 年 9 月 に提供してくれた、Stuart Williams と Norman Walsh、そして他の TAG メンバーにも感謝しています。また、Semantic Web Deployment Group のメンバー Michael Hausenblas、Vit Novacek、Ed Summers らが 2007 年 10 月 に行ったレビューとそのまとめにも感謝しています。最後に、草稿段階にあったこの文書をレビューしてくれた皆さん、特に Chris Bizer、Gunnar AAstrand Grimnes、Harry Halpin、Xiaoshu Wang、Henry S. Thompson、Jonathan Rees、Christoph Päper に感謝しています。また Susie Stephens は SWEO のマネジメントを行い、この文書をレビューするなど、私たちの活動を下支えしてくれました。Ivan Herman は W3C の要件に適合しているかを確認し、この note を提出してくれました。
この文書の作成は German Federal Ministry of Education, Science, Research and Technology (BMBF)、(Grants 01 IW C01, Project EPOS: Evolving Personal to Organizational Memories; and 01 AK 702B, Project InterVal: Internet and Value Chains) および European Union IST fund (Grant FP6-027705, Project Nepomuk) のサポートにより実現しました。
Common
HTTP Implementation Problems, Olivier Théreaux, Editor.
World Wide Web Consortium, 28 January 2003. This edition is
http://www.w3.org/TR/2003/NOTE-chips-20030128/. The latest
edition is available at http://www.w3.org/TR/chips/.
RDF
Primer, Frank Manola, Eric Miller, Editors. World Wide Web
Consortium, 10 February 2004. This edition is
http://www.w3.org/TR/2004/REC-rdf-primer-20040210/. The latest edition is available
at http://www.w3.org/TR/rdf-primer/.
RDF/XML
Syntax Specification (Revised), Dave Beckett, Editor. World
Wide Web Consortium, 10 February 2004. This edition is
http://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/. The latest edition is
available at http://www.w3.org/TR/rdf-syntax-grammar/.
Best
Practice Recipes for Publishing RDF Vocabularies, Alistair
Miles, Thomas Baker, Ralph Swick, Editors. World Wide Web Consortium,
23 January 2008. This edition is
http://www.w3.org/TR/2008/WD-swbp-vocab-pub-20080123/. It is a work in
progress. The latest
edition is available at http://www.w3.org/TR/swbp-vocab-pub/.
RFC 2616:
Hypertext Transfer Protocol - HTTP/1.1, J. Gettys, J. Mogul,
H. Frystyk, L. Masinter, P. Leach, T. Berners-Lee. IETF, 1999. This
document is available at http://www.ietf.org/rfc/rfc2616.txt.
Semantic
Wikipedia, Max Völkel, Markus Krötzsch, Denny Vrandecic,
Heiko Haller, Rudi Studer. University of Karlsruhe, 2006. This document
is available at
http://www.aifb.uni-karlsruhe.de/WBS/hha/papers/SemanticWikipedia.pdf.
URNs,
Namespaces and Registries, Henry S. Thompson, David Orchard.
World Wide Web Consortium, 17 August 2006. This edition is
http://www.w3.org/2001/tag/doc/URNsAndRegistries-50-2006-08-17.html. It
is a work in progress. The latest
edition is available at
http://www.w3.org/2001/tag/doc/URNsAndRegistries-50.html.
RDF
Triples in XML, Jeremy J. Carroll, Patrick Stickler, 2004.
This document is available at
http://www.mulberrytech.com/Extreme/Proceedings/html/2004/Stickler01/EML2004Stickler01.html.
Hypertext Transfer
Protocol, Wikipedia contributors. Wikipedia, 8 October 2007.
The latest version of this document is available at
http://en.wikipedia.org/wiki/HTTP.
Leo Sauermann included more feedback from reviews contributed by TAG,
SWD, and Tim Berners-Lee.
8 December 2007
Danny Ayers did proofreading, minor grammar/idiomatic/editorial changes (I've tried not
to make any changes that substantively modify the content, though some
come close...). XHMTL validated with nxml-mode emacs
12 December 2007
Leo Sauermann included link to GRDDL as suggested by Danny Ayers, minor
changes of todo notes. Document was remodelled to Working Draft status - all
feedback by SWD, TAG, and Tim Berners Lee either has been addressed or is
listed in this document as todos using @@-symbols and the css class "todo".